LLM-SQL Tools
I reviewed SQL-LLM-Agent tools and libraries, sorted by GitHub stars. I just searched repo tags matching #llm #sql and similars.
It may not be complete yet, this blog is open to extension/update.
Pandas AI
![]()
PandasAI is a Python platform that makes it easy to ask questions to your data in natural language. It helps non-technical users to interact with their data in a more natural way, and it helps technical users to save time, and effort when working with data.
Usage is as easy as the code below to compare multiple dataframes:
import pandasai as pai
from pandasai_docker import DockerSandbox
from pandasai_openai.openai import OpenAI
employees_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Name': ['John', 'Emma', 'Liam', 'Olivia', 'William'],
'Department': ['HR', 'Sales', 'IT', 'Marketing', 'Finance']
}
salaries_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Salary': [5000, 6000, 4500, 7000, 5500]
}
llm = OpenAI("OPEN_AI_API_KEY")
pai.config.set({
"llm": llm
})
employees_df = pai.DataFrame(employees_data)
salaries_df = pai.DataFrame(salaries_data)
pai.chat("Who gets paid the most?", employees_df, salaries_df, sandbox=sandbox)
It also allows you to define columns explanations as “semantic layers” so that it produces more meaningful answers.
dataset = pai.create(path="organization/heart",
name="Heart",
description="Heart Disease Dataset",
df = file_df,
columns=[
{
"name": "Age",
"type": "integer",
"description": "Age of the patient in years"
},
...
]
And it supports to chat with your database or your datalake (SQL, CSV, parquet).
Vanna AI
“Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.”
This is a useful tool for non-AI engineers wanting to connect LLM to their DBs, and LLM techniques used in this library seems solid. It supports nearly %99 of VectorDBs, Databases, LLM APIs.
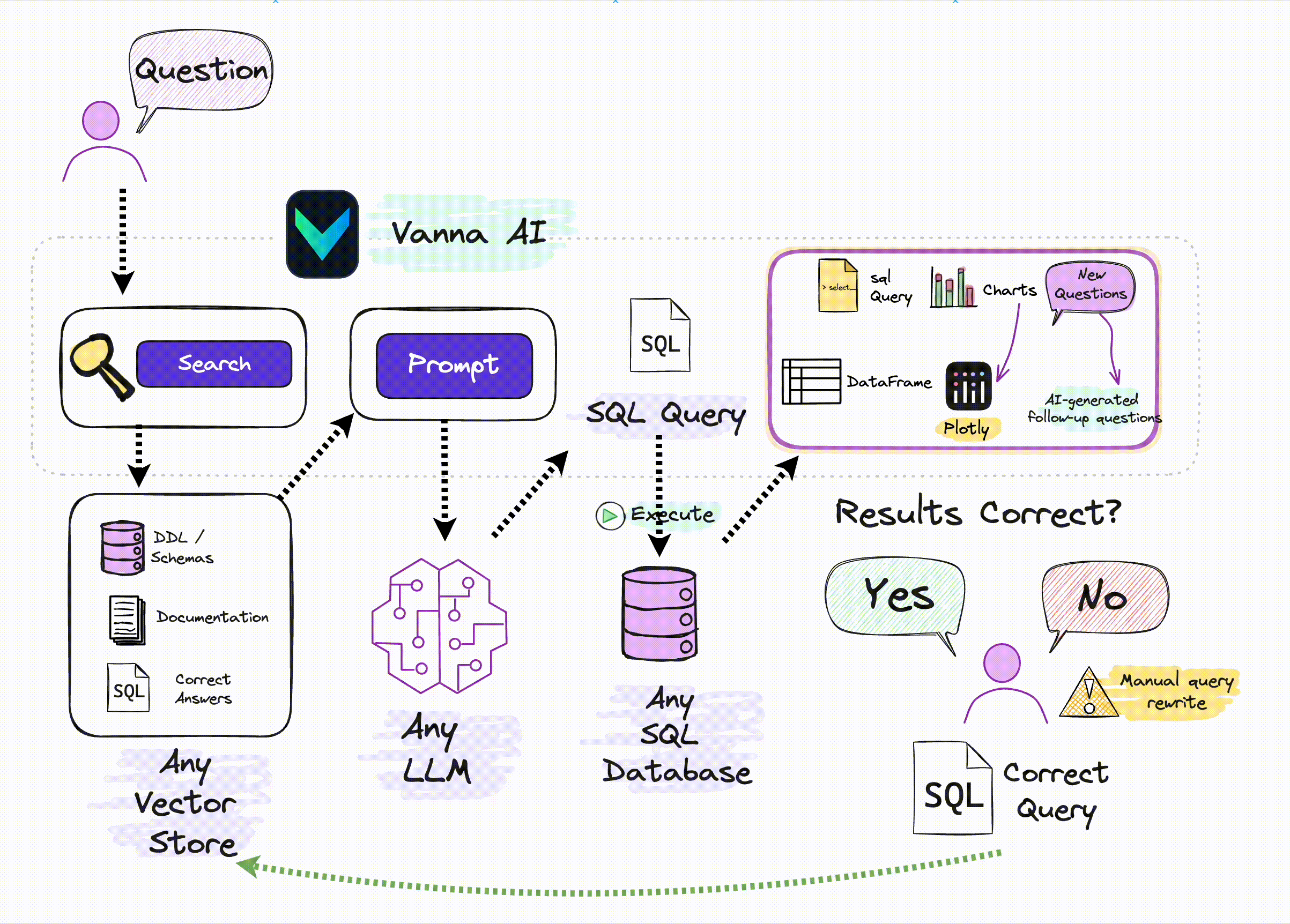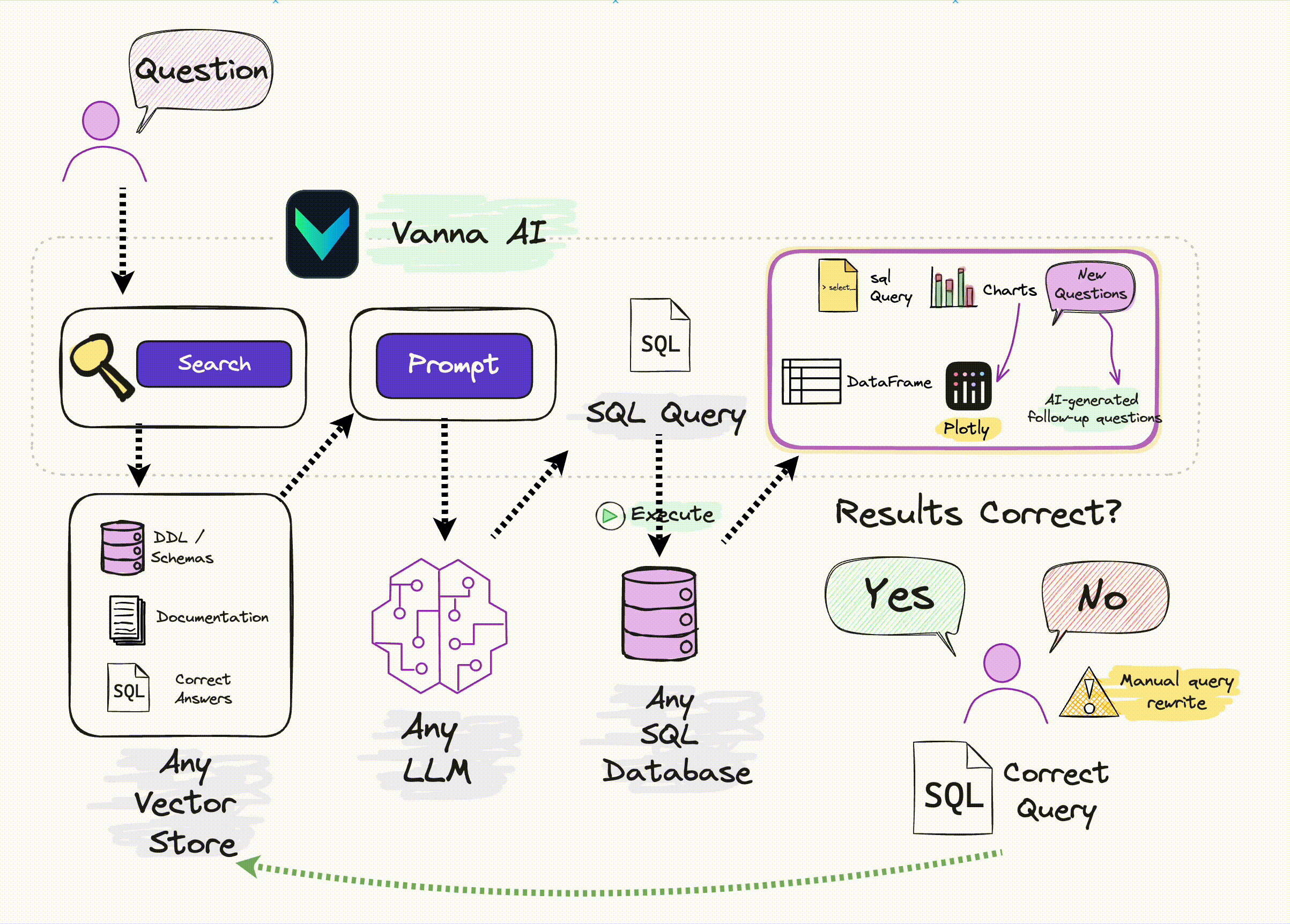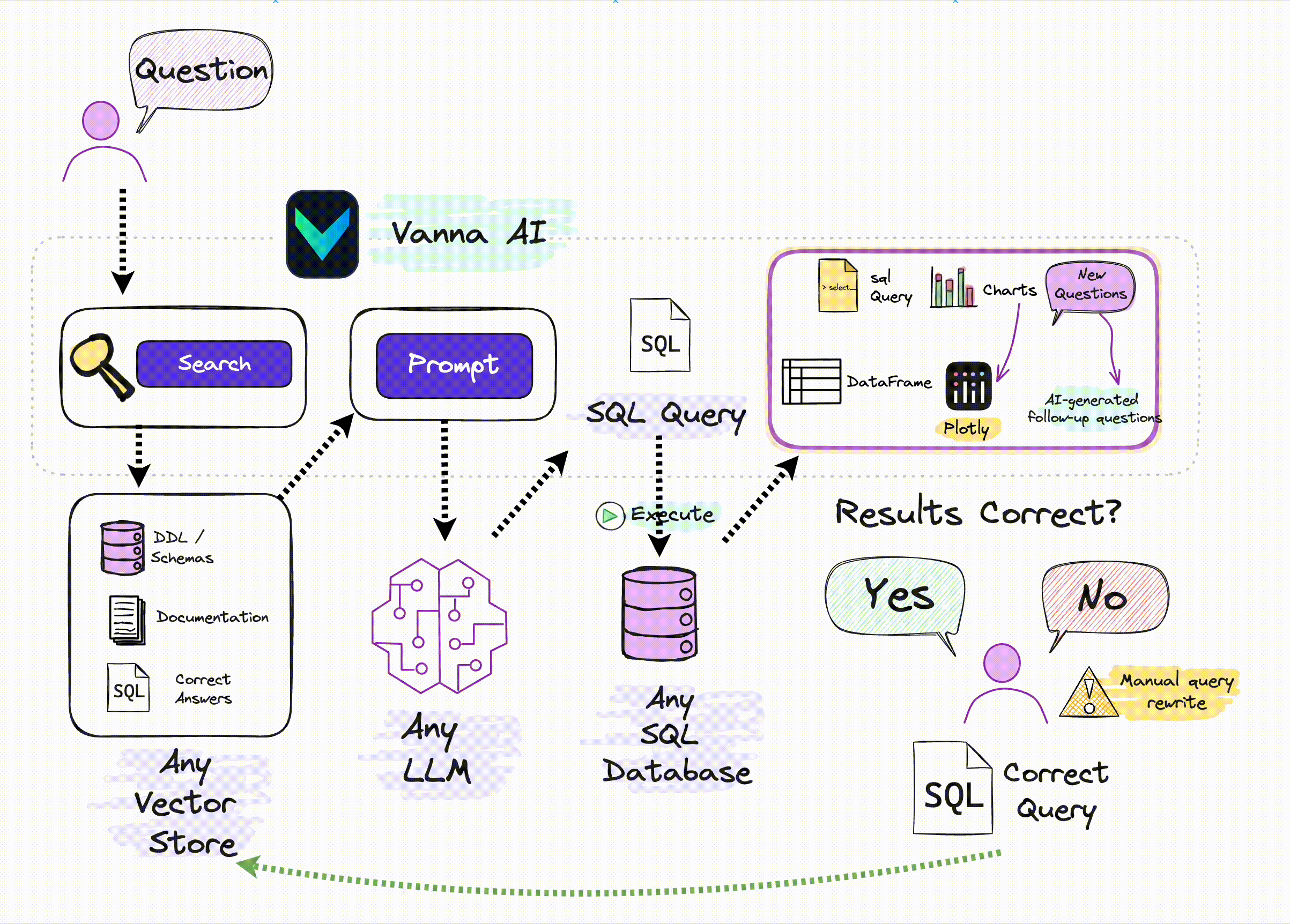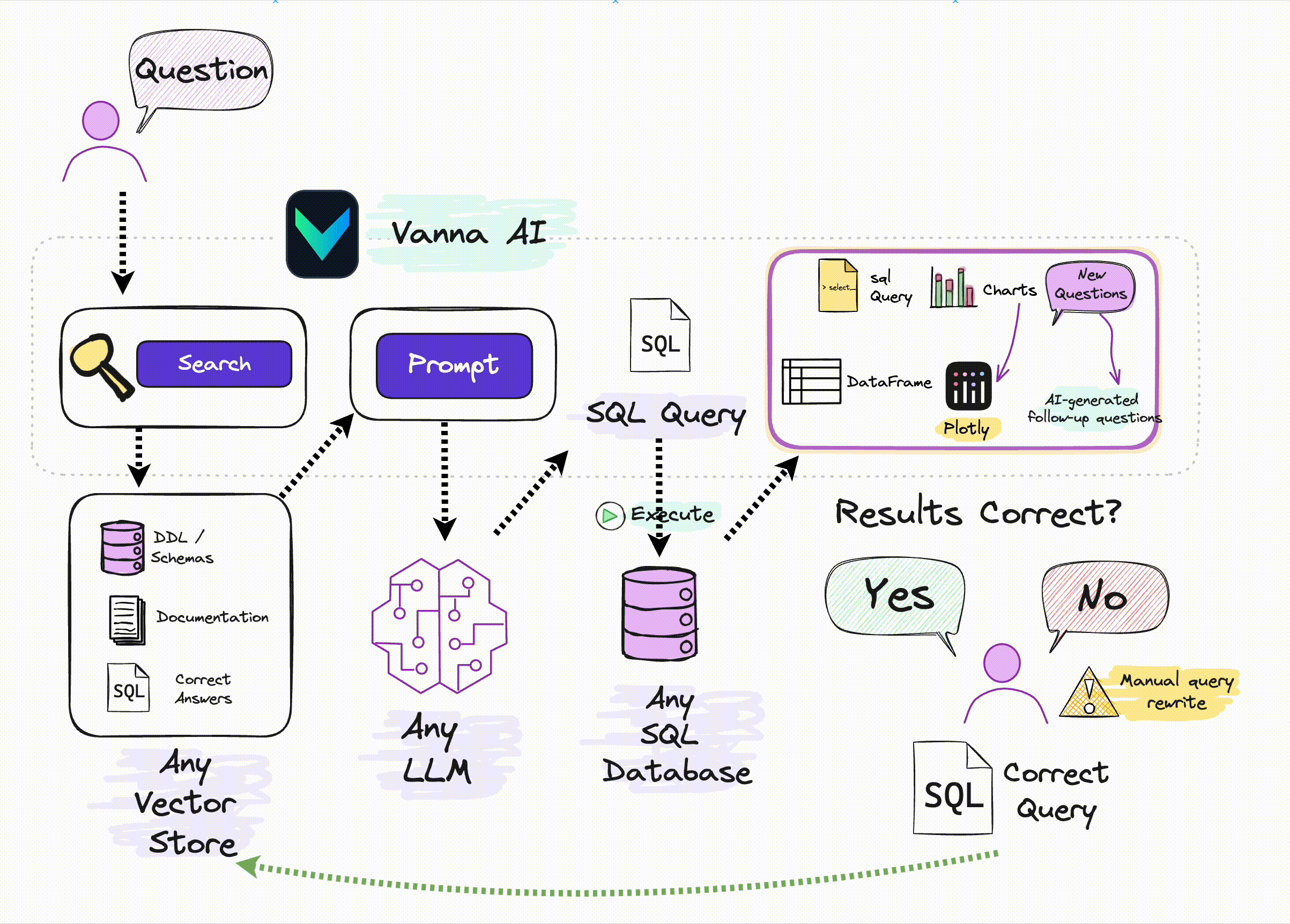
It uses RAG to “train” (which is a confusing name) to your DBs. In terms of AI language, correct name would be “teach”, at least I would name it that way. It consumes one/all of:
- Data Definition Language (DDL) statements
These statements give the system an understanding of what tables, columns, and data types are available.
vn.train(ddl="CREATE TABLE my_table (id INT, name TEXT)")
- Documentation strings
These can be any abtirary documentation about your database, business, or industry that may be necessary for the LLM to understand how the context of a user’s question.
vn.train(documentation="Our business defines XYZ as ABC")
SQL Statements
vn.train(sql="SELECT col1, col2, col3 FROM my_table")
Question-SQL Pairs
Train the system with question-SQL pairs. This is the most direct way to train the system and is the most helpful for the system to understand the context of the questions that are being asked.
vn.train(
question="What is the average age of our customers?",
sql="SELECT AVG(age) FROM customers"
)
They also have UI, the thing I would be adding as a feature would be thumbs up/down feature, if I don’t like the query or the output, and ask user to reason it. So in a similar query, LLM would look at the table. They have some similar feature but not sure if they do it.
Overall, liked it. If I would be developing some similar tool, I would do the exactly same.
Wren AI
BI Tools that utilises LLM to analyse your SQL Data.
Fancier than Vanna AI, reason may be Wren advertise itself as Generative Business Intelligence Agent (GenBI Agent). So the audience is more : Data teams who want a plug-and-play GenBI platform. Not directly targeted for the developers who want to build custom agents on top of SQL.
One thing I noticed : On Wren’s SQL generation pipelines, planning (CoT) is shown to be tracked.
Wren’s engine is well-defined, similar to Vanna AI, a brilliant system that incorporates DB knowledge into RAG’s (and Vector DBs) naturally :

As an output they have a UI, that any non-technical user can generate reports/charts/summaries and save them.
And amazing blog by Wren to explain the system design.
The blog is worth to read, and explains why they have developed semantic engine to understand more relations between tables/columns.
In order to achieve optimal performance and accuracy from LLMs, simply having DDL and schema definitions is not sufficient.
LLMs need to comprehend the relationships between various entities and understand the calculation formulas used within your organization. Providing additional information such as calculations, metrics, and relationships (join paths) is essential for helping LLMs understand these aspects. Gross profit margin equals (Revenue — Cost of Goods Sold) / Revenue LLMs might already be powerful enough … However, in the real world the columns are usually messy, and revenue might be set as column name rev , and we will probably see rev1, pre_rev_1, rev2
- LLMs have no way of understanding what they mean without semantic context.
So that they’ve developed their own semantic, SQL-compliant modeling syntax.
 .
.
Kudos to the work!
PostgresML
Unfortunately it’s discontinued.
It’s a Postgres extension to bring ML capabilities to your DB, including 47+ classification and regression algorithms on GPU. The focus is on LLMs, I’ll introduce that. I like the name “in-database” machine learning.
The only prerequisites for using PostgresML is a Postgres database with our open-source pgml extension installed.
And not much of a documentation on LLMs. So unfortunately I’m skipping that.
Dataherald AI
Another abandoned project. Offering similar but limited features to the Vanna AI and Wren AI.
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over relational data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to:
Allow business users to get insights from the data warehouse without going through a data analyst Enable Q+A from your production DBs inside your SaaS application Create a ChatGPT plug-in from your proprietary data
DB-GPT-Hub
It’s a library to fine tune your models and benchmark against SQL dataests.
Dataline
Just another Chat-with-your-data tool. No multi-step agents, working locally, but simple and good.
 .
.
Korvus
Just like PostgresML, Korvus is a Postgres extension.
Korvus is an all-in-one, open-source RAG (Retrieval-Augmented Generation) pipeline built for Postgres. It combines LLMs, vector memory, embedding generation, reranking, summarization and custom models into a single query, maximizing performance and simplifying your search architecture.
It’s binded to Python on RAG, stores vector DB results to PG table.
Assume its ChromaDB, not stored in SQLite.
async def rag():
query = "Is Korvus fast?"
print(f"Querying for response to: {query}")
results = await collection.rag(
{
"CONTEXT": {
"vector_search": {
"query": {
"fields": {"text": {"query": query}},
},
"document": {"keys": ["id"]},
"limit": 1,
},
"aggregate": {"join": "\n"},
},
"chat": {
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a friendly and helpful chatbot",
},
{
"role": "user",
"content": f"Given the context\n:\nAnswer the question: {query}",
},
],
"max_tokens": 100,
},
},
pipeline,
)
print(results)
asyncio.run(rag())
Anyquery
That’s an interesting tool.
![]()
Anyquery is a quirky but powerful CLI tool that lets you run SQL queries on almost anything — APIs, apps, local files, even logs.
Think of it like sqlite + a Swiss Army knife: it turns random data sources into SQL tables you can query, join, and even update.
I really don’t know who demands that, but it makes sense to have some unified way to access data of any app.
Anyquery exposes a uniform SQL interface over diverse data sources such as:
- Apple Notes
- GitHub stars/issues
- Hacker News
- Notion
- Airtable
- Google Sheets
- CSV / JSON / Parquet files
- Local logs
- Spotify, Pocket, Raindrop, etc.
You can write queries like:
-- List all repos starred by @rauchg
SELECT * FROM github_stars_from_user('rauchg');
And yeah you can chat with your apps, too. Check the demo.