Clever Chunking Methods Aren’t (Always) Worth the Effort
 |
I was reading about fancy chunking strategies on RAG systems. There are endless ways of chunking which most of them makes sense.
Reading through it, I’ve even seen technical blog posts/papers that mentions 25 ways of chunking?!? Then I realised it’s not about the fanciness of the methods but how much performance you gain by an effort.
Lots of readings/podcasts of Frank Liu (former CTO of Zillus, now VoyageAI acquired by MongoDB), and Lanchain CTO, and Greg Kamradt’s 5 levels of text splitting, I’ve found two sophisticated methods to test:
1) Proposition Models
2) Semantic Chunking
Then, I read the paper by Renyi Qu et. al., that discusses Is Semantic Chunking Worth the Computational Cost?.
Paper simply discusses that:
- Semantic Chunking is indifferent or negligible performance boost.
- Although it still may be beneficial to test it on your data that It may be beneficial case-by-case, it’s not a dominantly winning solution.
And want to validate the results on a toy case.
Replicate the study without GPU, clone from GitHub.
Note : Notebook is reproducible, all data is cached so you can execute the notebook with no embedding(or GPU) needed, it’s still very fast on CPU.
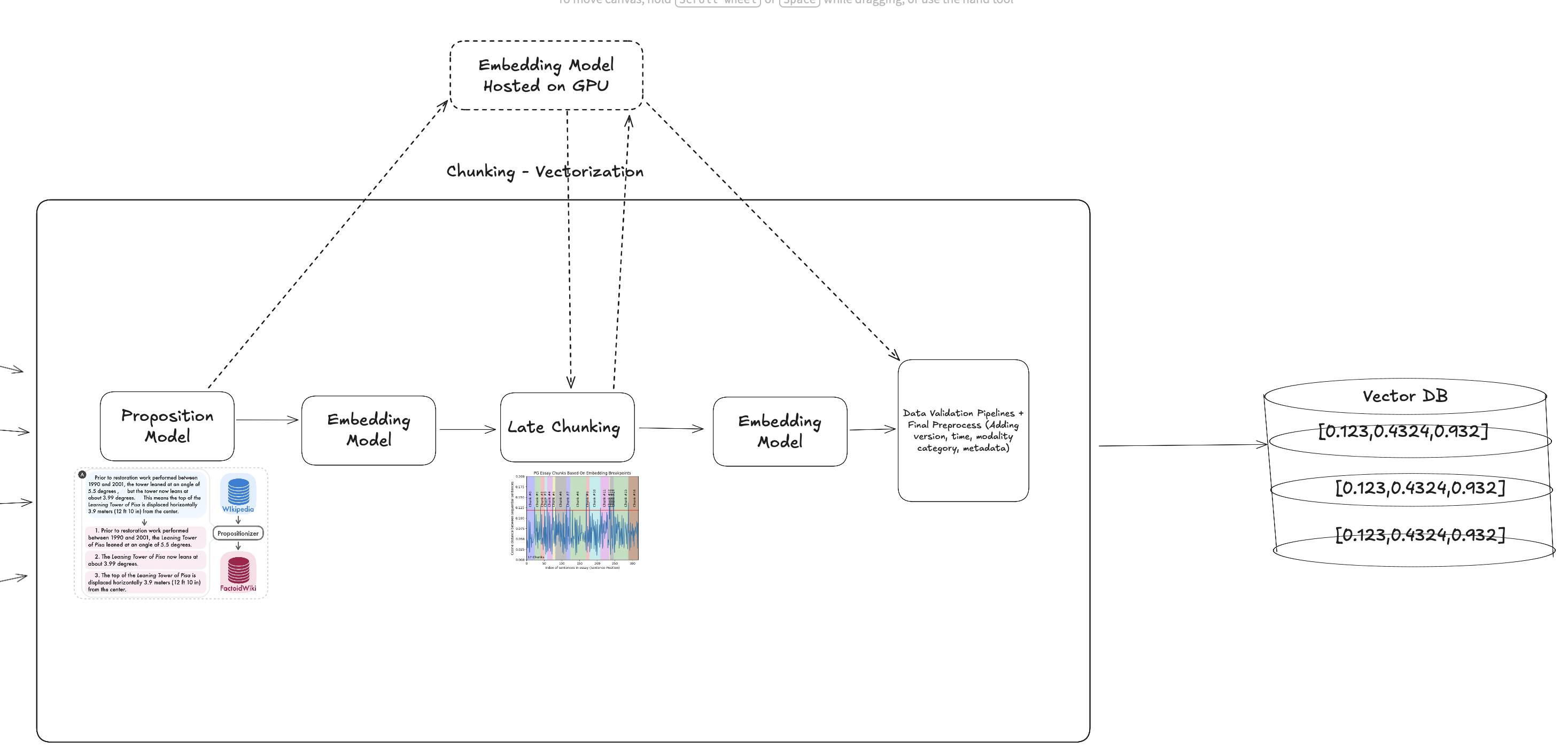
Proposition Method

Proposition method (famous paper of Dense x retrieval: What retrieval granularity should we use? ) simply defends that subjects and pronouns in any language mixed into different chunks makes retrieval problem harder, so we need to rename those into real names.
Assume:
-
(ending of) Chunk 1 : The Eiffel tower is so long.
-
(beginning of) Chunk 2 : The tower is in Paris.
Since the embeddings are different across thousands of chunks, we may not retrieve the tower is in Paris.
A simple LLM can do that, but to make it less costly and use proposed models of the authors, you can get into the HF page to access.
The method seems like a perfect fit to be used in legal documents, having lots of subjects and pronouns that needs to be expanded.
Although on retrieval stage, you can retrieve them via ParentRetriever/AutomergingRetriever kind of algorithms that brings nearby chunks, we won’t take that into account for the sake of evaluation. I have discussed that later on.
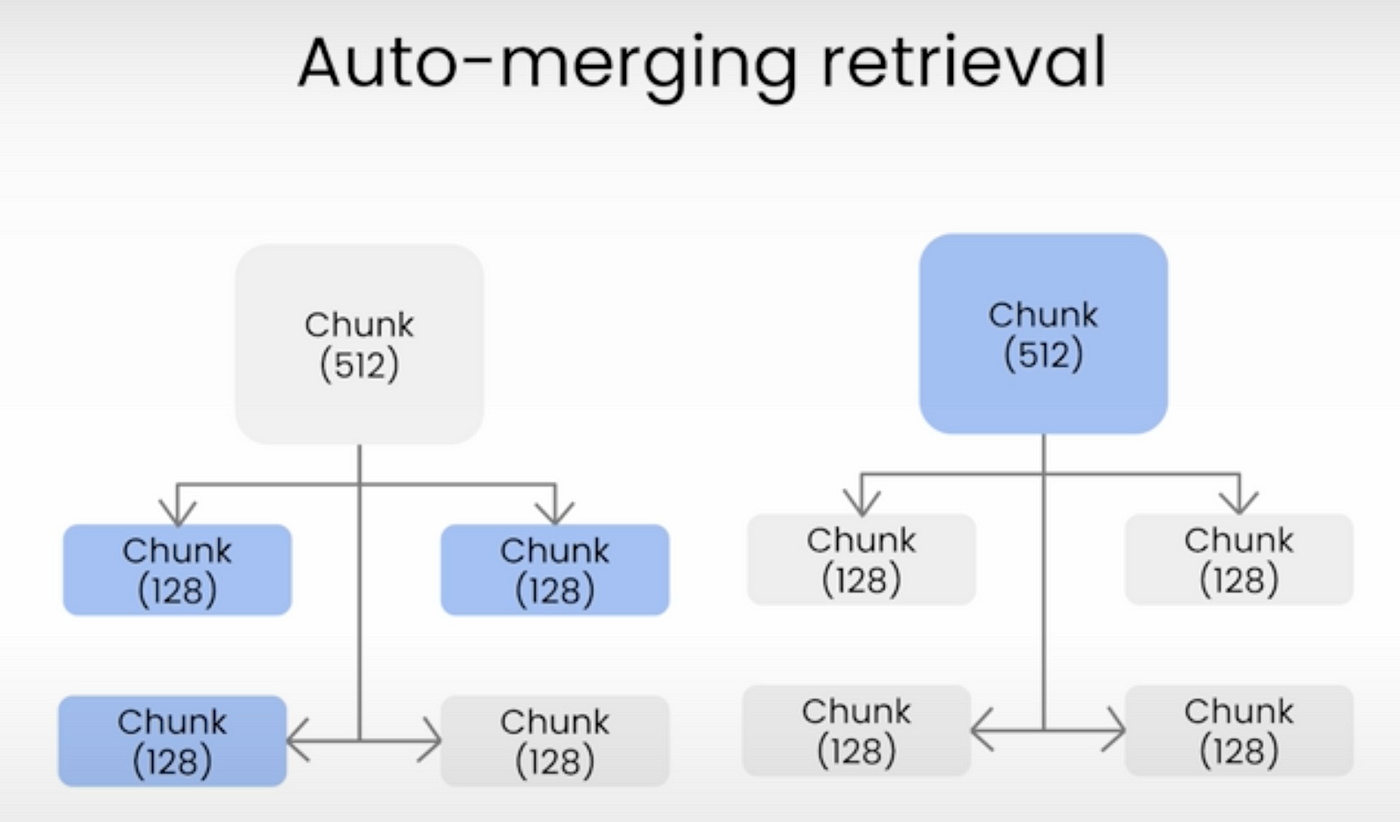
Automerging Retriever alone would eliminate most of the problems but we won’t use it to test retrieval effect
Semantic Chunking

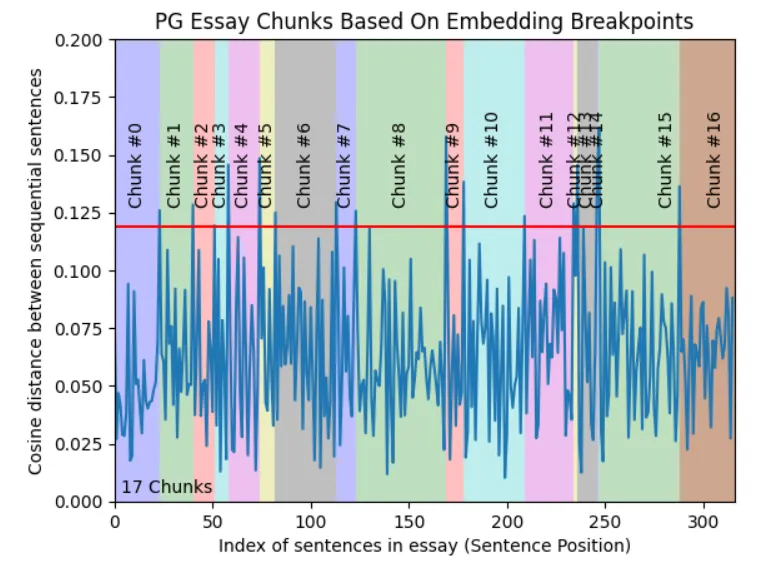
Greg Kamradt’s famous “5 levels of text splitting for retrieval” mentions about the technique that is not so complex, but not so simple but also promising, that a semantic difference–based approach where the model measures the change in meaning between consecutive sentences and starts a new chunk whenever the context shifts.
They both makes sense, they should work?
That’s correct, it should work at least. In fact, you can overlap chunks, use query enhancer, rerankings via LLM API calls, but at what cost? Probably all the things you do will improve the performance of retrieval, however there should be “does it worth the effort?” point.
A beautiful illustration by Lance Martin, Langchain, showing how complex can RAG systems be (even without conversation agents)
Retrieval Evaluation vs. RAG Evaluation
RAG systems as I’ve posted how complex can it be, requires evaluation techniques that evaluates the response of the system :
To evaluate RAG systems :
- LLM-as-a-judge, deepEval having easy-but-elegant solutions.
- RAGAS measures metrics like faithfulness, context precision, and answer correctness.
- Human evaluation
- and so on
However, to evaluate retrieval systems :
- Precision@k
- Recall@k
- F1@k
- Mean Reciprocal Rank (MRR)
which are classical information retrieval metrics. I talk about the metrics in a detailed manner in my previous blog, check it out.
We are choosing retrieval evaluation, because if we can’t retrieve good, complexity of RAG systems won’t really matter
Suppose you have very complex agentic RAG system, can it work if your retrieval scores are bad? I don’t think so. It’s the heart of our system, and agents we build around it is brain, complex document processors are bones, query enhancers are livers etc. But without heart they are meaningless.
So we’ll test complexity with the simple metrics.
What do we compare against
We’ll compare againts:
1) Simple chunking, filling till maximum embedding capacity
2) Proposition Model + Paragraph Chunking
3) Simple Chunking + Semantic Chunking
4) Proposition Model + Semantic Chunking
We’ll test every component of this final design.
Let’s Code
Not all parts are in the blog, you can access full codebase at :
I’m including key implementations in here.
Embedding Model : E5-Small
Both Langchain CEO and Milvus/VoyageAI (Frank Liu again) CTO advises E5, especially Frank Liu advises it multiple times.
Performance concerns, I’ll go with E5-small.
Vector Database : Qdrant
I love Qdrant because it’s easy to setup, bug-free mostly, and allows hybrid search although we won’t use it in the case for fair evaluation of dense based methods.
Dataset : EUR-Lex
I converted 900 few pages of EUR-LEX json to pdf. It offers access to EU legal documents, available in all 24 official EU languages and updated on a daily basis. It’s on GitHub of this project, don’t worry.
Why Proposition Models Makes Sense (at least at first glimpse) for Legal Documents
The proposition has such an effect on EUR-LEX data :
| Original Sentence | Rewritten / Equivalent Sentence |
|---|---|
| `Having received` an Opinion from the Commission. | `The Council shall receive` an Opinion from the Commission. |
Sentence Splitting : Load Spacy Model
We’ll use spacy model to divide into sentences, for our semantic embeddings only solution.
Reading Docs
PDFs look like the text below, for every doc. You can also see original pdfs in the GitHub.
Click to expand Python code
Having regard to Article 83 of the Treaty establishing the European Economic Community, which provides that an advisory committee consisting of experts designated by the Governments of Member States shall be attached to the Commission and consulted by the latter on transport matters whenever the Commission considers this desirable, without prejudice to the powers of the transport section of the Economic and Social Committee; Having regard to Article 153 of that Treaty, which provides that the Council shall, after receiving an opinion from the Commission, determine the rules governing the committees provided for in that\n\nTreaty;\n\nHaving received an Opinion from the Commission;\n\n## Main Body:\n\nthat the Rules of the Transport Committee shall be as follows:\n\nThe Committee shall consist of experts on transport matters designated by the Governments of Member States. Each Government shall designate one expert or two experts selected from among senior officials of the central administration. It may, in addition, designate not more than three experts of acknowledged competence in, respectively, the railway, road transport and inland waterway sectors.\n\nEach Government may designate an alternate for each member of the Committee appointed by it; this alternate shall satisfy conditions the same as those for the member of the Committee whom he replaces.\n\nAlternates shall attend Committee meetings and take part in the work of the Committee only in the event of full members being unable to do so.\n\nCommittee members and their alternates shall be appointed in their personal capacity and may not be bound by any mandatory instructions.\n\nThe term of office for members and their alternates shall be two years. Their appointments may be renewed.\n\nIn the event of the death, resignation or compulsory retirement of a member or alternate, that member or alternate shall replaced for the remainder of his term of office.\n\nThe Government which appointed a member or alternate may compulsorily retire that member or alternate only if the member or alternate no longer fulfils the conditions required for the performance of his duties.\n\nThe Committee shall, by an absolute majority of members present and voting, elect from among the members appointed by virtue of their status as senior officials of the central administration a Chairman and Vice-Chairman, who shall serve as such for two years. Should the Chairman or Vice-Chairman cease to hold office before the period for which he was elected has expired, a replacement for him shall be elected for the remainder of the period for which he was originally elected.\n\nNeither the Chairman nor the Vice-Chairman may be re-elected.\n\nThe Committee shall be convened by the Chairman, at the request of the Commission, whenever the latter wishes to consult it. The Commission’s request shall state the purpose of the consultation.\n\nWhen the Committee is consulted by the Commission, it shall present the latter with a report setting out the conclusions reached as a result of its deliberations. It shall do likewise if the Commission entrusts it with the study of a specific problem. The Commission shall also be entitled to consult the Committee orally. The minutes of the Committee shall be sent to the Commission.\n\nThe Commission shall be invited to send its representatives to meetings of the Committee and its working parties.\n\nThe Committee shall, by an absolute majority of members present and voting, adopt rules of procedure laying down its methods of working.\n\nThe Committee may, whenever such action appears to it to be necessary for the purposes of formulating an opinion, seek the assistance of any suitably qualified person, obtain any advice and hold hearings. Such action may, however, be taken only with the consent of the Commission.\n\n0\n\nThe expenses of the Committee shall be included in the estimates of the Commission.\n\n## Attachments:\n\nDone at Brussels, 15 September 1958.\n\nFor the Council The President L. Erhard
Preparing Data of Simple Chunking
Simple chunking divides text into 500 character chunks with very little cautions to not break sentences if possible.
Click to expand Python code
def chunk_by_characters(text: str, chunk_size: int = 500) -> List[str]:
"""Split text into chunks of approximately chunk_size characters, avoiding word breaks."""
if not text:
return []
chunks = []
start = 0
text_len = len(text)
while start < text_len:
# Get chunk end point
end = start + chunk_size
if end >= text_len:
# Last chunk
chunks.append(text[start:].strip())
break
# Find the last space before end to avoid breaking words
chunk = text[start:end]
last_space = chunk.rfind(' ')
if last_space != -1:
end = start + last_space
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append(chunk_text)
start = end + 1 # Skip the space
return [c for c in chunks if c] # Remove empty chunks
# Test
test_text = "This is a test. " * 50
test_chunks = chunk_by_characters(test_text, 450)
print(f"Test: {len(test_text)} chars -> {len(test_chunks)} chunks")
print(f"Chunk sizes: {[len(c) for c in test_chunks[:3]]}")
print(f"Sample Chunk : {test_chunks[:2]}")
Test: 800 chars -> 2 chunks
Chunk sizes: [447, 351]
Sample Chunk : ['This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test.', 'This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test. This is a test.']
Prepare Data for Chunk by Paragraph
Paragraph chunking divides text into parahraphswith very little cautions to not break paragraphs if possible.
Click to expand Python code
def chunk_by_paragraph(text: str, max_chars: int = 600) -> List[str]:
"""Heuristically split text into paragraphs, breaking long ones at sentence boundaries."""
if not text:
return []
text = re.sub(r'\s+', ' ', text.strip())
raw_paragraphs = re.split(r'\n\s*\n', text)
paragraphs = []
for para in raw_paragraphs:
para = para.strip()
if not para:
continue
sentences = re.split(r'(?<=[.!?])\s+', para)
current, length = [], 0
for sent in sentences:
if len(sent) > max_chars:
# Cut long sentence into hard slices
for i in range(0, len(sent), max_chars):
paragraphs.append(sent[i:i+max_chars].strip())
continue
if length + len(sent) > max_chars:
if current:
paragraphs.append(" ".join(current).strip())
current, length = [], 0
current.append(sent)
length += len(sent)
if current:
paragraphs.append(" ".join(current).strip())
return paragraphs
Prepare Data for Semantic Chunking
Watch Greg Kamradt’s 5 levels of text splitting for detailed explanation, simply what is being done is:
-
Divide text into sentences
-
Embed sentences
-
If cosine difference between chunks are jumping, it means context switch, Put a breakpoint
-
Group chunks and re-embed for final version.
Click to expand Python code
def chunk_semantic(
text: str,
nlp_model,
embedding_model: EmbeddingModel,
percentile_threshold: float = 85.0
) -> List[str]:
"""Semantic chunking using sentence embeddings and breakpoint detection."""
# Step 1: Split into sentences
sentences = chunk_by_sentences(text, nlp_model)
if len(sentences) <= 1:
return sentences
# Step 2: Embed all sentences in batch (efficient!)
embeddings = embedding_model.embed(sentences, batch_size=BATCH_SIZE, show_progress=False)
# Step 3: Calculate cosine distances between adjacent sentences
distances = []
for i in range(len(embeddings) - 1):
# Cosine similarity
sim = np.dot(embeddings[i], embeddings[i + 1])
# Convert to distance
dist = 1.0 - sim
distances.append(dist)
if not distances:
return sentences
# Step 4: Find breakpoints using percentile threshold
threshold = np.percentile(distances, percentile_threshold)
breakpoints = [i for i, d in enumerate(distances) if d > threshold]
# Step 5: Group sentences between breakpoints into chunks
chunks = []
start_idx = 0
for breakpoint in breakpoints:
end_idx = breakpoint + 1
chunk = " ".join(sentences[start_idx:end_idx])
if chunk:
chunks.append(chunk)
start_idx = end_idx
# Add remaining sentences
if start_idx < len(sentences):
chunk = " ".join(sentences[start_idx:])
if chunk:
chunks.append(chunk)
return chunks if chunks else sentences
Create Qdrant Vector Database
Let’s create collection for each method, you can find them on the notebook and the GitHub.
Build an Evaluation Dataset of (Query, Context) Pairs
To test our system, I devised a similar approach to the one LlamaIndex uses, as demonstrated in their retriever evaluation examples. The evaluation data is generated by Large Language Models (LLMs) using highly effective prompts.
Prompt Structure:
- Create a question/answer pair for this document.
- Grab a single fact from the document and rephrase it into lazy, human language (the question).
- Provide the source text as well.
Evaluate by Chunks (Varying per Method)
We’ll use the original text and chunks from the source document to ensure a fair evaluation.
For each question, we’ll check if the retrieved document (or chunk) includes the specific source sentence (the fact). If it does, it’s counted as a “hit.”
Evaluating Proposal Methods (A Slight Nuance)
A key difference is that proposal methods slightly change the text. For these methods, we’ll utilize semantic embedding for evaluation.
What this means:
Normally, in vector search, we compare:
- User Query $\rightarrow$ Doc Embeddings (semantic similarity between the query and the documents)
In our evaluation pipeline, since we know we generated a question based on a specific source sentence (the “ground truth text”), we can query:
- Ground Truth Text $\rightarrow$ Doc Embeddings (semantic similarity between the ground truth text and the documents)
This is a valid and robust method if you want to avoid using a costly or slow LLM-as-a-judge approach.
The provided code reads PDFs, randomly selects a section, generates num_questions_per_pdf, and stores the original source text. We will strictly use this original text during our evaluations, not the text generated by the proposal method.
Evaluation and Retrieval Function
As mentioned, for standard methods, we check if the chunk contains the target sentence. If a proposition method is used, we’ll check if the factual sentence is semantically similar (>70%) to the proposition chunk using embeddings.
Click to expand Python code
def evaluate_collection_by_chunk_hit(
client: QdrantClient,
collection_name: str,
questions: List[Dict[str, str]],
embedding_model: EmbeddingModel,
mode: str = "semantic", # "semantic" or "literal"
top_k: int = 10,
similarity_threshold: float = 0.7,
batch_size: int = 8,
) -> List[Dict[str, Any]]:
"""
Evaluate retrieval performance.
Modes:
- "literal": string inclusion match (case-insensitive)
- "semantic": embedding cosine similarity (same document only)
"""
results = []
print(f"\nEmbedding {len(questions)} questions for Qdrant retrieval...")
question_texts = [q["question"] for q in questions]
question_embeddings = embedding_model.embed(
question_texts, batch_size=batch_size, show_progress=True
)
print(f"Evaluating collection '{collection_name}' in {mode.upper()} mode...")
for q_idx, q in enumerate(tqdm(questions)):
query_emb = question_embeddings[q_idx]
retrieved = retrieve_from_qdrant(client, collection_name, query_emb, top_k)
retrieved_texts = [r["text"] for r in retrieved]
retrieved_sources = [r["source"] for r in retrieved]
gt_text = q["ground_truth_chunk"].strip()
source_file = q.get("source_file", "").strip()
same_doc_indices = [i for i, s in enumerate(retrieved_sources) if s == source_file]
hit, rank, best_similarity = False, None, 0.0
if not same_doc_indices:
results.append({
"question": q["question"],
"source_file": source_file,
"ground_truth_chunk": gt_text,
"retrieved_sources": retrieved_sources,
"hit": False,
"rank": None,
"best_similarity": 0.0,
})
continue
# 🔹 LITERAL MODE
if mode == "literal":
gt_norm = normalize_text(gt_text)
for local_idx, chunk in enumerate([retrieved_texts[i] for i in same_doc_indices]):
chunk_norm = normalize_text(chunk)
if gt_norm in chunk_norm or chunk_norm in gt_norm:
global_idx = same_doc_indices[local_idx]
hit, rank = True, global_idx + 1
best_similarity = 1.0
break
# 🔹 SEMANTIC MODE
elif mode == "semantic":
gt_emb = embedding_model.embed([gt_text])[0]
same_doc_texts = [retrieved_texts[i] for i in same_doc_indices]
same_doc_embs = embedding_model.embed(same_doc_texts)
sims = cosine_similarity([gt_emb], same_doc_embs)[0]
best_similarity = float(np.max(sims)) if len(sims) else 0.0
for local_idx, sim in enumerate(sims):
if sim >= similarity_threshold:
global_idx = same_doc_indices[local_idx]
hit, rank = True, global_idx + 1
break
results.append({
"question": q["question"],
"source_file": source_file,
"ground_truth_chunk": gt_text,
"retrieved_chunks": retrieved_texts,
"retrieved_sources": retrieved_sources,
"hit": hit,
"rank": rank,
"best_similarity": best_similarity,
})
total_hits = sum(r["hit"] for r in results)
print(f"\n✅ {mode.upper()} Evaluation: {total_hits}/{len(results)} hits "
f"({total_hits/len(results)*100:.1f}%)")
return results
Define Metrics
Metric functions are truncated, you can find it on repo.
Main Execution Pipeline
# Load all PDFs
pdf_texts = load_all_pdfs(PDF_FOLDER)
# Initialize embedding model with MPS
embedding_model = EmbeddingModel(EMBEDDING_MODEL, device)
✓ Successfully loaded 100 PDFs ```python # Setup Qdrant qdrant_client = setup_qdrant_collections() ```
✓ Initialized local Qdrant at: ./local_qdrant_chunking_eval
Apply Proposition + Paragraph Chunking
propositionized_docs = propositionize_documents_with_local(pdf_texts, device)
How does proposition look like
| Original Legal Text | Propositionized Output |
|---|---|
| That the Rules of the Transport Committee shall be as follows: | ⚠️ The Rules of the Transport Committee shall consist of experts on transport matters designated by the Governments of Member States. |
Click to expand to see more proposition effect!
| Original Legal Text | Propositionized Output |
|---|---|
| Having regard to Article 153 of that Treaty, which provides that the Council shall, after receiving an opinion from the Commission, determine the rules governing the committees provided for in that Treaty; | Article 153 of the Treaty provides for the Council to determine the rules governing the committees provided for in that Treaty after receiving an opinion from the Commission. |
| Having received an Opinion from the Commission; | ⚠️ The Council shall receive an Opinion from the Commission. |
| That the Rules of the Transport Committee shall be as follows: | ⚠️ The Rules of the Transport Committee shall consist of experts on transport matters designated by the Governments of Member States. |
| The Committee shall consist of experts on transport matters designated by the Governments of Member States. | Each Government shall designate one expert or two experts selected from among senior officials of the central administration. |
| It may, in addition, designate not more than three experts of acknowledged competence in, respectively, the railway, road transport and inland waterway sectors. | Each Government may designate not more than three experts of acknowledged competence in the railway, road transport, and inland waterway sectors. |
| Each Government may designate an alternate for each member of the Committee appointed by it; this alternate shall satisfy conditions the same as those for the member of the Committee whom he replaces. | Each Government may designate an alternate for each member of the Committee appointed by it. The alternate shall satisfy conditions the same as those for the member of the Committee whom he replaces. |
| Committee members and their alternates shall be appointed in their personal capacity and may not be bound by any mandatory instructions. | Committee members and their alternates shall be appointed in their personal capacity. Committee members and their alternates may not be bound by any mandatory instructions. |
| The term of office for members and their alternates shall be two years. Their appointments may be renewed. | The term of office for members and their alternates shall be two years. Appointments for members and their alternates may be renewed. |
| In the event of the death, resignation or compulsory retirement of a member or alternate, that member or alternate shall replaced for the remainder of his term of office. | In the event of the death, resignation, or compulsory retirement of a member or alternate, that member or alternate shall be replaced for the remainder of his term of office. |
Click to expand to see Python code!
print("\n" + "=" * 60)
print("METHOD 2: Proposition + Paragraph Chunking")
print("=" * 60)
start_time = time.time()
proposition_paragraph_chunks: List[Dict[str, Any]] = []
for pdf_path, proposition_text in propositionized_docs.items(): # dict from the async call
# Split the propositioned text into paragraph-sized chunks
for idx, chunk_text in enumerate(chunk_by_paragraph(proposition_text, max_chars=500)):
proposition_paragraph_chunks.append(
{
"text": chunk_text,
"source": pdf_path,
"chunk_index": idx,
"chunking_method": "proposition_paragraph",
}
)
store_chunks_in_qdrant(
qdrant_client,
COLLECTION_PROPOSITION_PARAGRAPH,
proposition_paragraph_chunks,
embedding_model,
BATCH_SIZE,
)
timing_stats["proposition_paragraph"] = time.time() - start_time
chunk_stats["proposition_paragraph"] = [len(c["text"]) for c in proposition_paragraph_chunks]
chunk_collections["proposition_paragraph"] = proposition_paragraph_chunks
print(
f"\n✓ Proposition + paragraph chunking: "
f"{len(proposition_paragraph_chunks)} chunks in {timing_stats['proposition_paragraph']:.2f}s"
)
timing_stats['proposition_paragraph'] = time.time() - start_time
chunk_stats['proposition_paragraph'] = [len(c['text']) for c in simple_chunks]
Apply Semantic + Character-Based Chunking and Proposition + Semantic Chunking
To see how effective the proposition model on semantic chunking, creating two collections in Qdrant and storing chunks separately.
To see effect of proposition + semantic chunking on the data, expand!
Proposed model proposes the text.
And in late chunking, pipeline checks if meaning shift between sentences exists.
Any sudden change on the different between vector embeddings, code defines a breakpoint, then chunking between breakpoints.
As you’ll see in example, it makes sense!!!
Final output via late chunking is :
.1. Article 83 of the Treaty establishing the European Economic Community provides for an advisory committee consisting of experts designated by the Governments of Member States. The advisory committee shall be attached to the Commission and consulted on transport matters whenever the Commission considers it desirable. The advisory committee shall not prejudice the powers of the transport section of the Economic and Social Committee.
.2. Article 153 of the Treaty provides for the Council to determine the rules governing the committees provided for in that Treaty after receiving an opinion from the Commission. The Council shall receive an Opinion from the Commission. The Rules of the Transport Committee shall consist of experts on transport matters designated by the Governments of Member States. Each Government shall designate one expert or two experts selected from among senior officials of the central administration. Each Government may designate not more than three experts of acknowledged competence in the railway, road transport, and inland waterway sectors. Each Government may designate an alternate for each member of the Committee appointed by it. The alternate shall satisfy conditions the same as those for the member of the Committee whom he replaces.
.3. Alternates shall attend Committee meetings and take part in the work of the Committee only in the event of full members being unable to do so. Committee members and their alternates shall be appointed in their personal capacity. Committee members and their alternates may not be bound by any mandatory instructions. The term of office for members and their alternates shall be two years. Appointments for members and their alternates may be renewed. In the event of the death, resignation, or compulsory retirement of a member or alternate, that member or alternate shall be replaced for the remainder of his term of office. The Government which appointed a member or alternate may compulsorily retire that member or alternate only if the member or alternate no longer fulfils the conditions required for the performance of his duties. The Committee shall elect a Chairman and Vice-Chairman from among the members appointed by virtue of their status as senior officials of the central administration. The Chairman and Vice-Chairman shall serve as such for two years. Should the Chairman or Vice-Chairman cease to hold office before the period for which he was elected has expired, a replacement for him shall be elected for the remainder of the period for which he was originally elected. Neither the Chairman nor the Vice-Chairman may be re-elected. The Chairman shall convene the Committee at the request of the Commission whenever the latter wishes to consult it.
.4. The Commission’s request shall state the purpose of the consultation.
.5. When the Committee is consulted by the Commission, it shall present the Commission with a report setting out the conclusions reached as a result of its deliberations. The Committee shall present the Commission with a report if the Commission entrusts it with the study of a specific problem. The Commission shall also be entitled to consult the Committee orally. The minutes of the Committee shall be sent to the Commission. The Commission shall be invited to send its representatives to meetings of the Committee and its working parties. The Committee shall adopt rules of procedure laying down its methods of working. The Committee may seek the assistance of any suitably qualified person, obtain any advice and hold hearings. Such action may be taken only with the consent of the Commission. The expenses of the Committee shall be included in the estimates of the Commission.
- The President of the Council is L. Erhard.
How does semantic chunking alone looks like:
Let’s assume we have 4 paragraphs talk about completely different complex. That’s how our pipeline divides them into chunks.
text_semantic_test = """The forest floor was covered with glowing mushrooms after the rain.
Birds sang strange melodies that echoed between the wet trees.
A fox darted between the shadows, its fur reflecting faint moonlight.
The new quantum chip surpassed classical supercomputers in energy efficiency.
Researchers claimed it could process entangled states in under a millisecond.
Some skeptics questioned whether the benchmarks were fair at all.
The baker woke at dawn to knead dough for the city’s largest sourdough loaf.
His hands were dusted with flour like a snowstorm in miniature.
By noon, the scent of baked bread filled every street corner.
Astronomers observed a rogue planet drifting between two galaxies.
It had no sun, no orbit, and radiated only its internal heat.
They nicknamed it “The Wanderer” in the press release.
The painter used coffee instead of paint for his latest collection.
Each stroke darkened or lightened as the caffeine dried unevenly.
Critics couldn’t decide whether it was genius or a caffeine accident.
The programmer trained a neural network to compose medieval lute music.
At first, it sounded like random notes, but slowly patterns emerged.
Within a week, the AI was producing haunting melodies fit for a cathedral.
Deep beneath the ocean, a species of jellyfish glowed like molten gold.
Divers recorded their b
"""
test_chunks = chunk_semantic(text_semantic_test, nlp, embedding_model, percentile_threshold=85.0)
for i in test_chunks:
print(f"Chunk : {i}\n\n")
Chunk : The forest floor was covered with glowing mushrooms after the rain. Birds sang strange melodies that echoed between the wet trees. A fox darted between the shadows, its fur reflecting faint moonlight.
Chunk : The new quantum chip surpassed classical supercomputers in energy efficiency. Researchers claimed it could process entangled states in under a millisecond. Some skeptics questioned whether the benchmarks were fair at all. The baker woke at dawn to knead dough for the city’s largest sourdough loaf. His hands were dusted with flour like a snowstorm in miniature. By noon, the scent of baked bread filled every street corner.
Chunk : Astronomers observed a rogue planet drifting between two galaxies. It had no sun, no orbit, and radiated only its internal heat. They nicknamed it “The Wanderer” in the press release. The painter used coffee instead of paint for his latest collection. Each stroke darkened or lightened as the caffeine dried unevenly. Critics couldn’t decide whether it was genius or a caffeine accident.
Chunk : The programmer trained a neural network to compose medieval lute music. At first, it sounded like random notes, but slowly patterns emerged. Within a week, the AI was producing haunting melodies fit for a cathedral. Deep beneath the ocean, a species of jellyfish glowed like molten gold. Divers recorded their b
Generate Evaluation Questions
Click to expand to see the evaluation code!
# Generate questions
print("\n" + "="*60)
print("GENERATING EVALUATION QUESTIONS")
print("="*60)
questions_cache_path = Path("questions.json")
if questions_cache_path.exists():
print(f"✓ Loading questions from {questions_cache_path}")
with questions_cache_path.open("r", encoding="utf-8") as f:
questions = json.load(f)
else:
questions = generate_questions_for_pdfs(
pdf_texts,
num_questions_per_pdf=1,
nlp_model=nlp,
openai_api_key=openai_api_key
)
with questions_cache_path.open("w", encoding="utf-8") as f:
json.dump(questions, f, ensure_ascii=False, indent=2)
print(f"✓ Saved questions to {questions_cache_path}")
============================================================
GENERATING EVALUATION QUESTIONS
============================================================
✓ Loading questions from questions.json
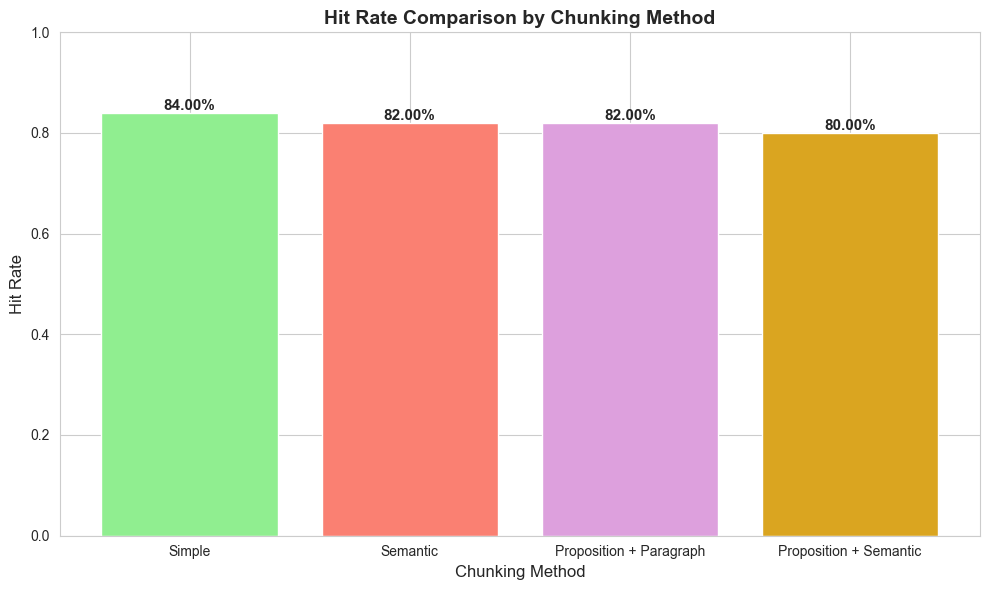
Turns out Simple No Brainer Chunking is Better (for this toy case)
Only negligible performance gains on some @k levels.
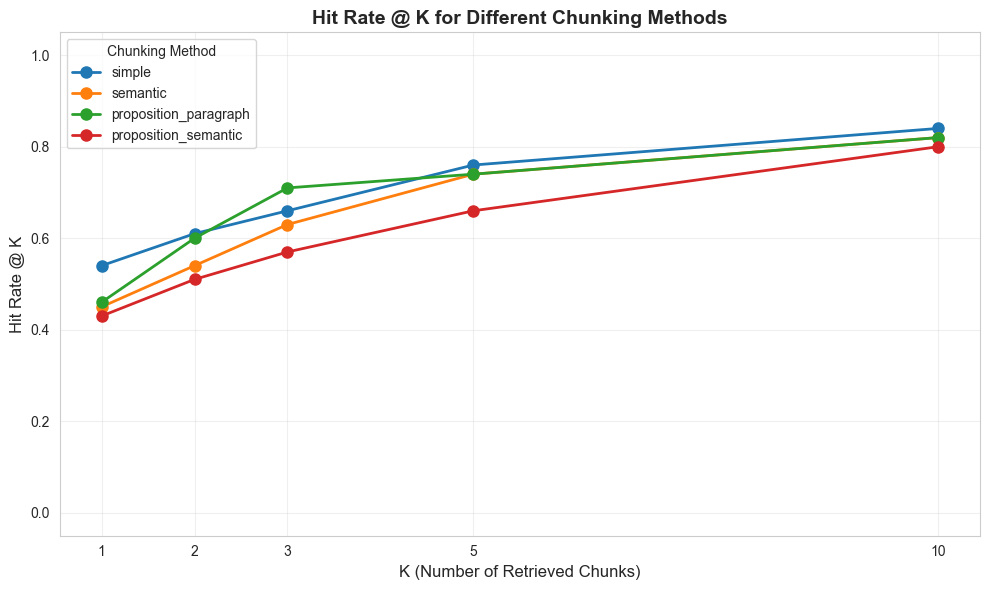
| hit_rate@1 | hit_rate@2 | hit_rate@3 | hit_rate@5 | hit_rate@10 | mrr | |
|---|---|---|---|---|---|---|
| simple | 54.00% | 61.00% | 66.00% | 76.00% | 84.00% | 62.52% |
| semantic | 45.00% | 54.00% | 63.00% | 74.00% | 82.00% | 55.96% |
| proposition_paragraph | 46.00% | 60.00% | 71.00% | 74.00% | 82.00% | 58.53% |
| proposition_semantic | 43.00% | 51.00% | 57.00% | 66.00% | 80.00% | 52.95% |
Visualize Metrics
Hit Rate @ 10
Simple dumb chunking is mostly better on all @k levels.
 |
Hit Rate @ K Curves
Simple dumb chunking is mostly better on all @k levels.
 |
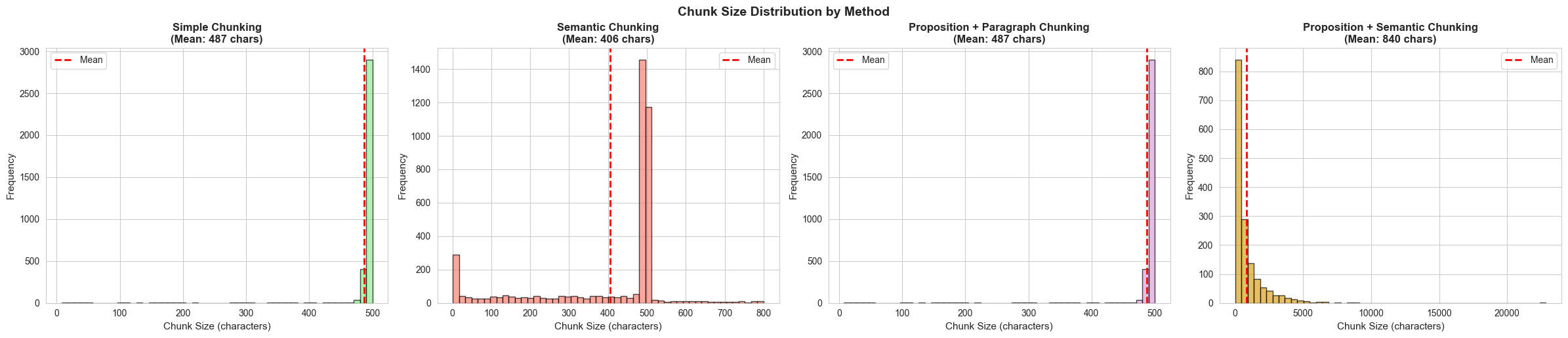
Chunk Size Distribution (Histogram)
 |
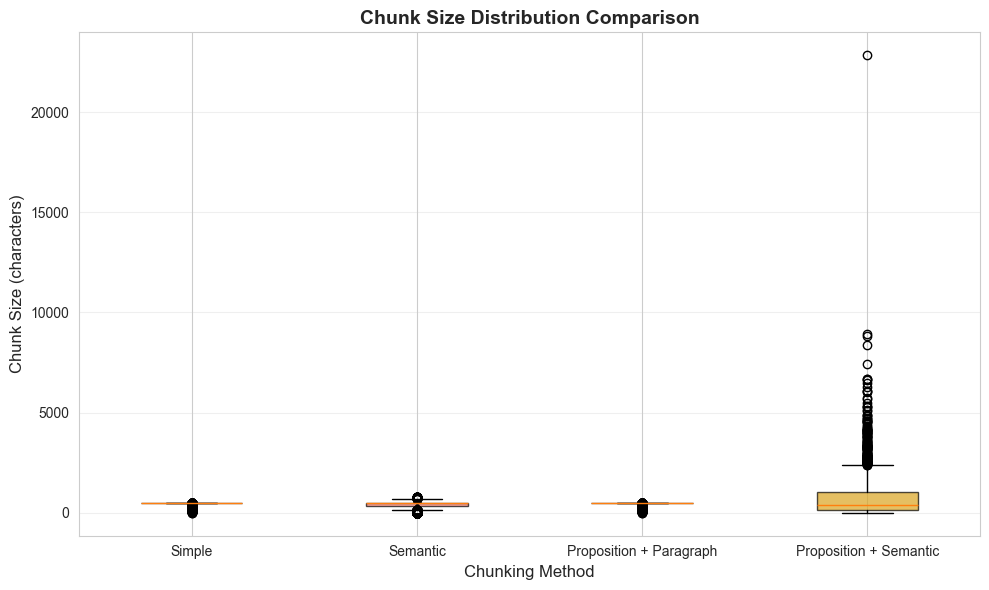
Chunk Size Comparison
- Semantic has a variation of chunk sizes due to context breakpoints.
- Other chunking methods, we just grabbed 500 characters.
 |
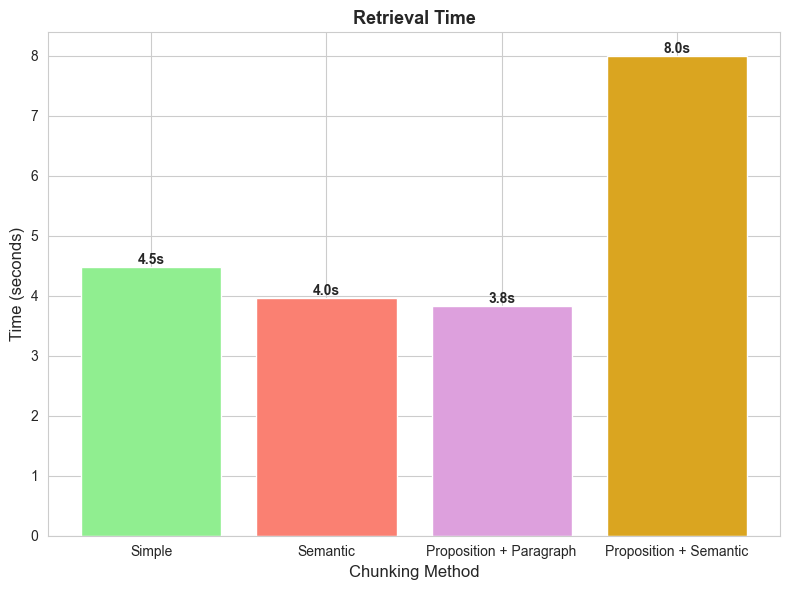
Performance Timing Chart
Does it worth the effort?
The amount that we prepare data is hard to justify, so I’m not including that.
- Proposition model requires either GPU or LLM, so it’ll have an additional computational cost.
- Semantic chunking alone is not so costly, it has a variation of chunk sizes due to context breakpoints.
 |
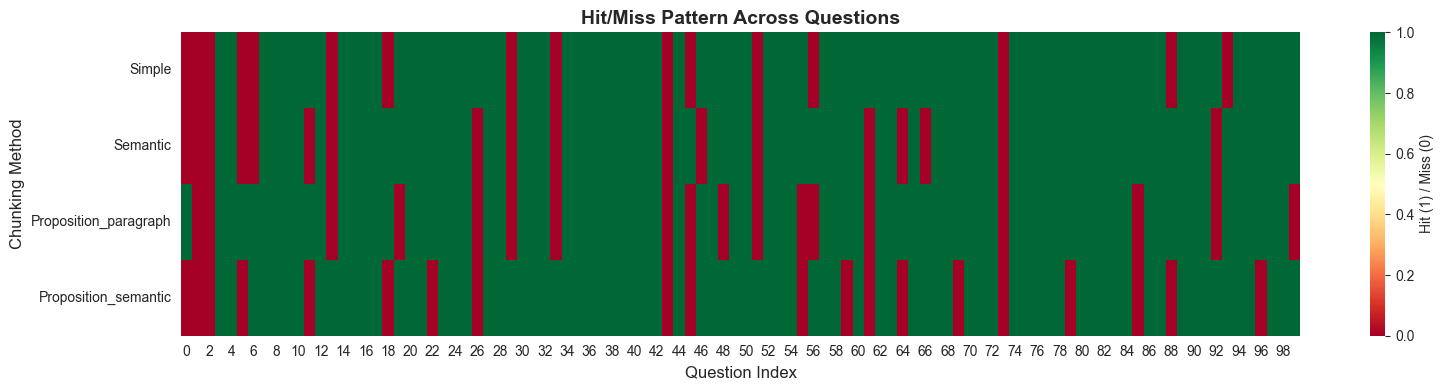
####13.7 Hit/Miss Pattern Heatmap
 |
Winner
🏆 BEST PERFORMING METHOD: SIMPLE Hit Rate: 84.00% MRR: 0.625
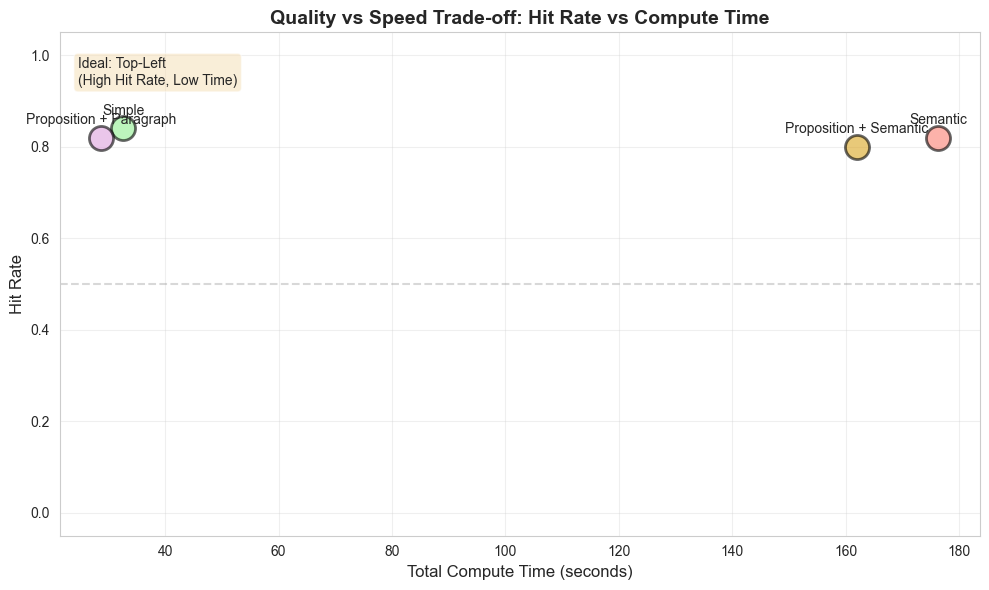
Efficiency Comparison: Hit Rate vs Compute Time (Scatter Plot)
 |
Why Semantic Chunking May Not Improve Performance
- It didnt improve much for the dataset I work with.
- It may have worked on a larger docs, but I have suspicions since Is Semantic Chunking Worth the Computational Cost? paper couldn’t see consistent performance improvements.
Theoretically:
- Possibly, embedding model is good enough to separate context. If you think on it, semantic chunking is grouping the text, and its few sentences more and few sentences less, embedding model will still run through all tokens and pool semantics into a meaningful vector.
- Context changes are session based, in the dataset within the same pdf chunks are already semantically similar.
- May be, embedding models are still good separator that can distinguish contextual differences within the single document.
Even if you have a large documents it may still not work because:
- Context of the paragraphs may have not change within the embedding size limits.
- If you are able to AutoMergingRetrieval, you can still get relevant documents by huge performance gains with no effort.
Why Proposition Models May Not Improve Performance
Again,
- It didnt improve much for the dataset I work with.
- It may result in performance gain in subject/nouns heavy dataset. I assumed it’s case for legal documents.
- However, although there are subject/nouns in the dataset, chunks are still discriminatory enough.
However, in critical cases that LLM Engineer wants to mention names in every chunk, and within queries if those subject/nouns are heavily employed, one can definitely benefit this approach.